
Summary Report COMET Introductory Sessions | November 7, 2024

By Adam Buttrrick, John Chodacki, Juan Pablo Alperin, Maria Praetzellis and Clare Dean
The introductory sessions for the Collaborative Metadata Enrichment Taskforce (COMET) were held on November 7, 2024. To accommodate different time zones, two sessions were held, hosting the same presentations at each and including a break for group discussion. The following provides a summary of the presented content and summarizes the discussions for both sessions. The sessions were convened and presented by John Chodacki (California Digital Library); Adam Buttrick (California Digital Library/ROR); Juan Pablo Alperin (Simon Fraser University/Public Knowledge Project); and Clare Dean (COMET).
Over 30 attendees participated in the initial meeting, including representatives from universities, publishers, government organizations, and service providers. For the full list of COMET participants, visit the “People” section of the COMET website.
Summary
The introductory meeting was held to outline the scope of COMET and what it aims to achieve, describing how the Taskforce itself will operate, as well as its goals, timeline, and scope.
The session provided context on how the project came into being, its overarching ideas and principles, and more concrete details on deadlines, deliverables, and expectations for participant involvement.
Group discussion was incorporated to clarify scope and intent, including what kinds of organizations are represented among the Taskforce participants and questions pertaining to the proposed workflows.
Based on initial community discussion, a draft vision statement was prepared for review during the meeting, allowing participants to orient their understanding of the goals of the Taskforce and the product it seeks to define.
Presentations
After a brief welcome to the session by the COMET Community Outreach Manager, Clare Dean, Juan Pablo Alperin provided an introduction to the scope of COMET.
Introduction: Juan Pablo Alperin
Juan began the session by identifying the fact that everyone involved with COMET has a love of PID metadata. He identified that all of COMET’s participants are also involved in building and using scholarly infrastructure in some way and have faced problems from this metadata being incorrect or incomplete.
Juan stressed that the presenters of today’s sessions are the conveners of COMET, whose role it is to bring the community together, facilitating, rather than directing, the course of discussions.
He then next framed the discussion using an overarching problem statement: “The current system for the maintenance and enrichment of PID metadata is inefficient and disconnected.” Juan stressed the reason that he and others are acting as conveners for this Taskforce is because they believe that addressing this problem is a shared responsibility, and not that of any one user, metadata creator, or service.
To provide further context about the origins of the Collaborative Metadata Enrichment Taskforce (COMET) Juan explained that it emerged from conversations had by many of the participants over the years. These conversations culminated in representatives from CDL organizing an initial, formal discussion to frame and better define these problems at the FORCE11 Conference, held over two days at the University of California Los Angeles in August of this year. This discussion was followed by an additional meeting in Paris as part of the Paris Conference on Open Research Information in September. The aim of both meetings was to solidify the community’s understanding of these shared challenges with metadata completeness and quality, so that they could work on a collaborative solution to resolve them. A summary of these conversations and the ideas that resulted from them led to the publication of two blog posts on the FORCE11 Upstream blog (the second also hosted on the COMET site) and, ultimately, the formation of COMET itself.

(slide 6)
Juan acknowledged that there are many different aspects and manifestations of these metadata problems across our ecosystem, but called for an articulation of a community solution that is concrete, manageable, so that we can begin work on tackling these challenges together.
Juan then clarified that the goal of the group is not to solve all of these problems themselves, but instead to come together and articulate what they are and how to address them, focusing on a solution where the community itself is able to enrich PID metadata. The Taskforce will work through the questions and concerns around this model, culminating in documentation for a call to action to be shared with the wider community for additional refinement, participation, and to pursue its implementation.
The COMET Taskforce: John Chodacki and Clare Dean
The presentation then pivoted to John and Clare addressing what tangibly the Taskforce will do over the course of the project. They explained that the Taskforce will work through a regimented process of listening sessions and drafting of documentation, with a focus on thinking through how the model developed by the Taskforce could be implemented by the wider community. John, following form Juan's sentiments, stressed that the Taskforce isn’t proposing to build something itself, but rather to articulate the product, technical, and governance considerations that underlie what needs to be built.

(slide 9)
He then noted that the timeline for this work is aggressive. The Taskforce wants to move quickly and decisively through its workstreams, such that a community call to action can be published in March of 2025.

(slide 10)
John then described how over the course of the Taskforce, members will participate in a series of listening sessions, beginning in November, where they will work with other members to define COMET’s product vision and goals, examine technical considerations, and the governance model that would best serve the proposed system. These will then inform a draft of a call to action in February of 2025 that can receive a final round of revisions and be issued by COMET to the community.
Clare then outlined COMET’s needs from participants to enable this work - to engage in the listening sessions, provide feedback on and/or co-create documentation that results from them; to participate in surveys and polls; and to publicly advocate for COMET’s vision and work.

(slide 11)
Proposed Workflows: Adam Buttrick
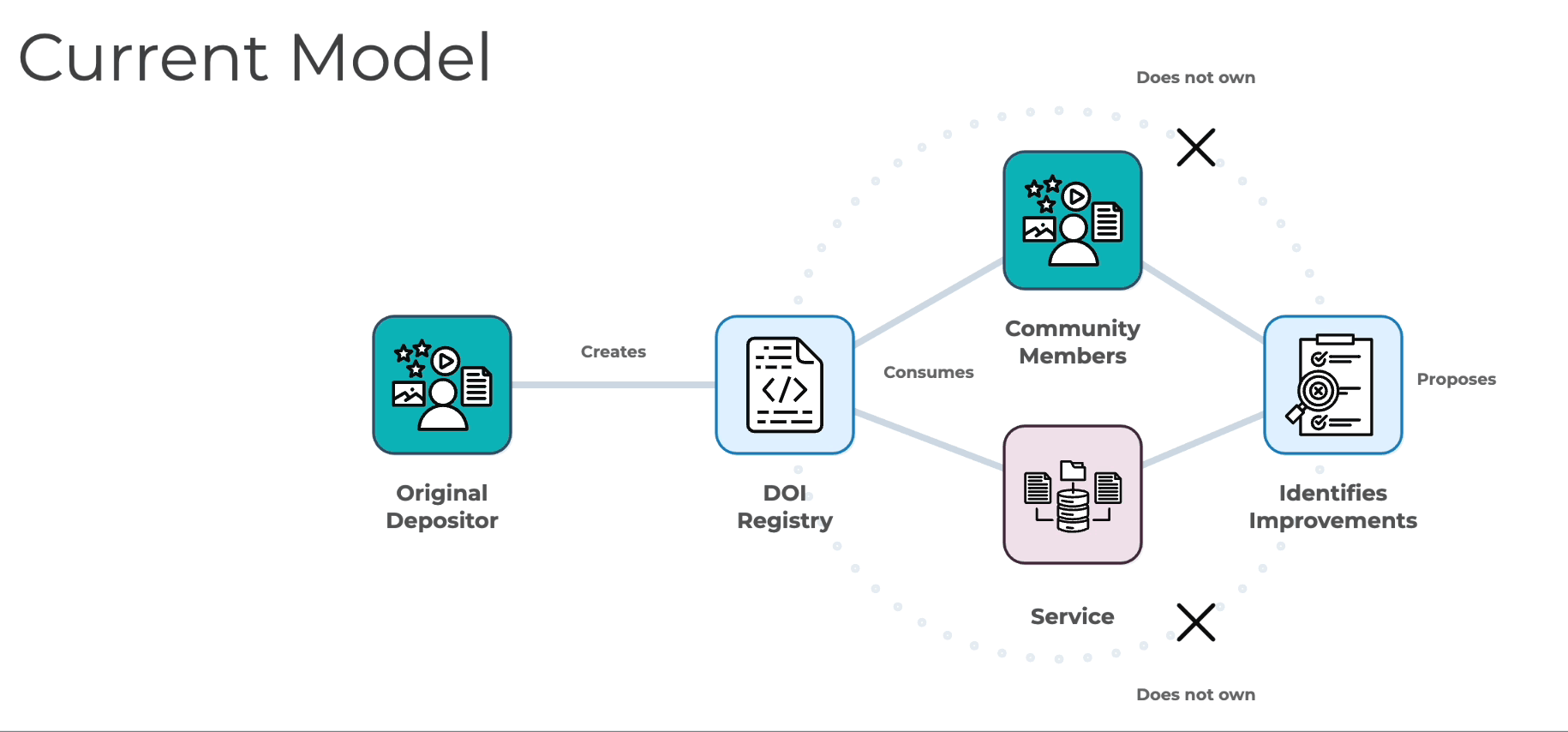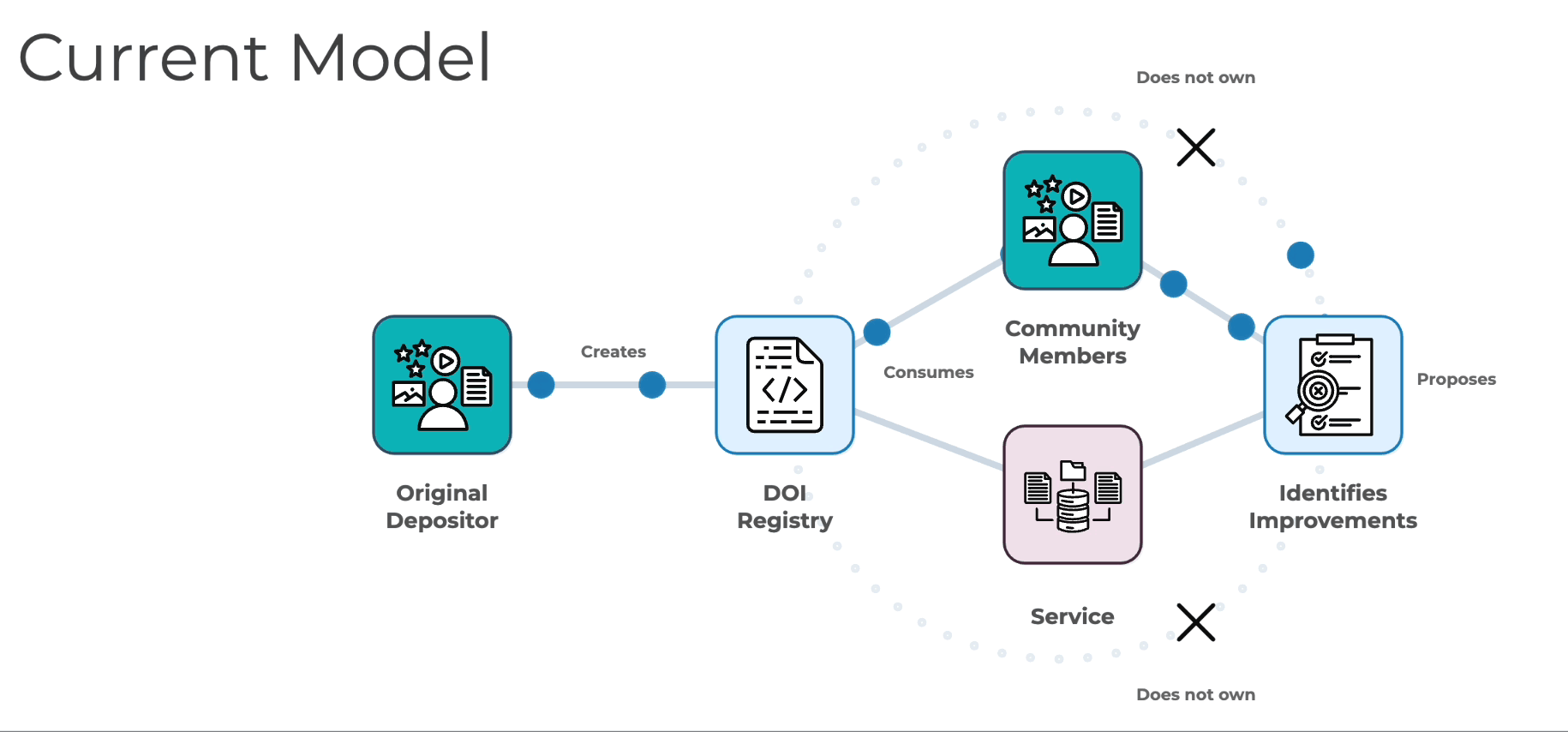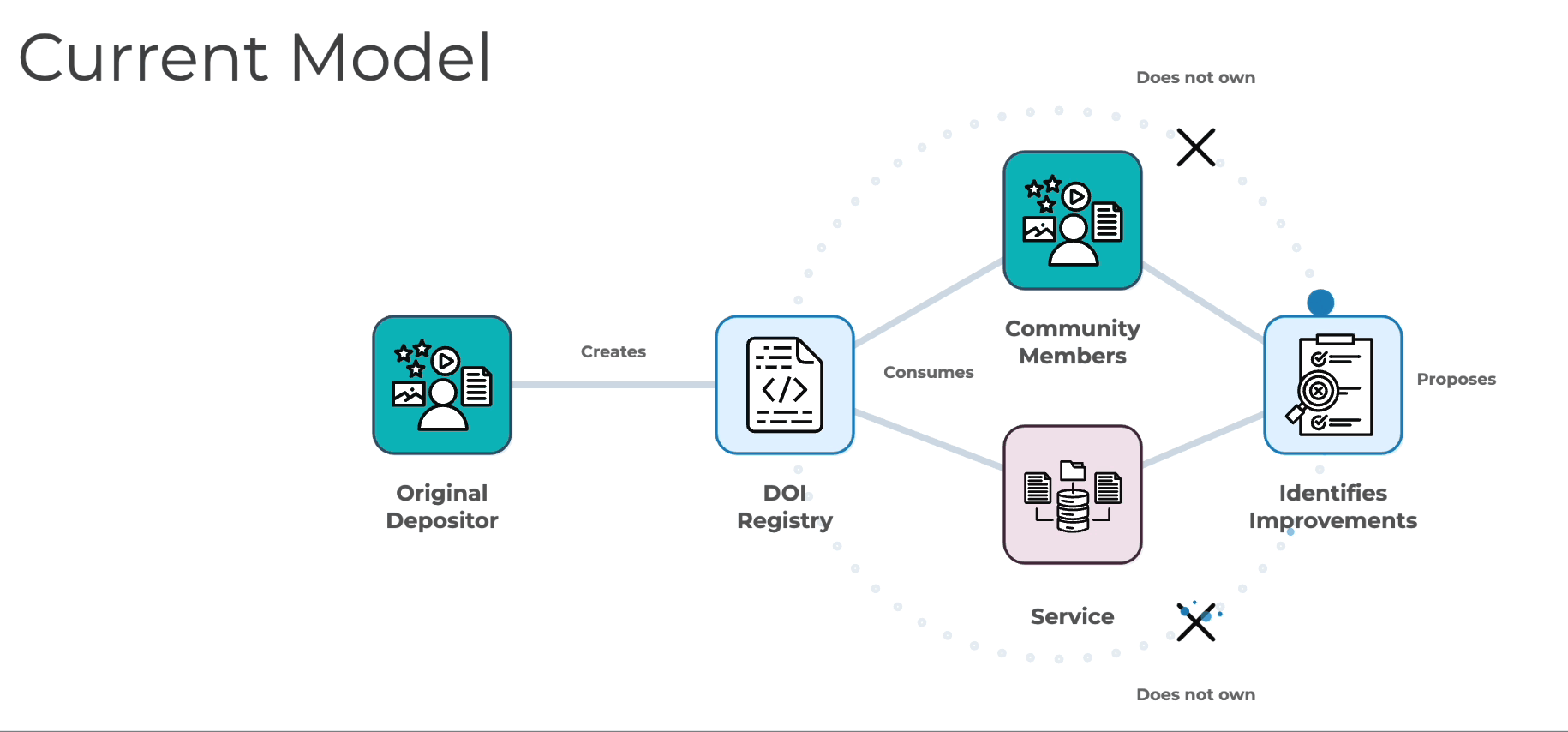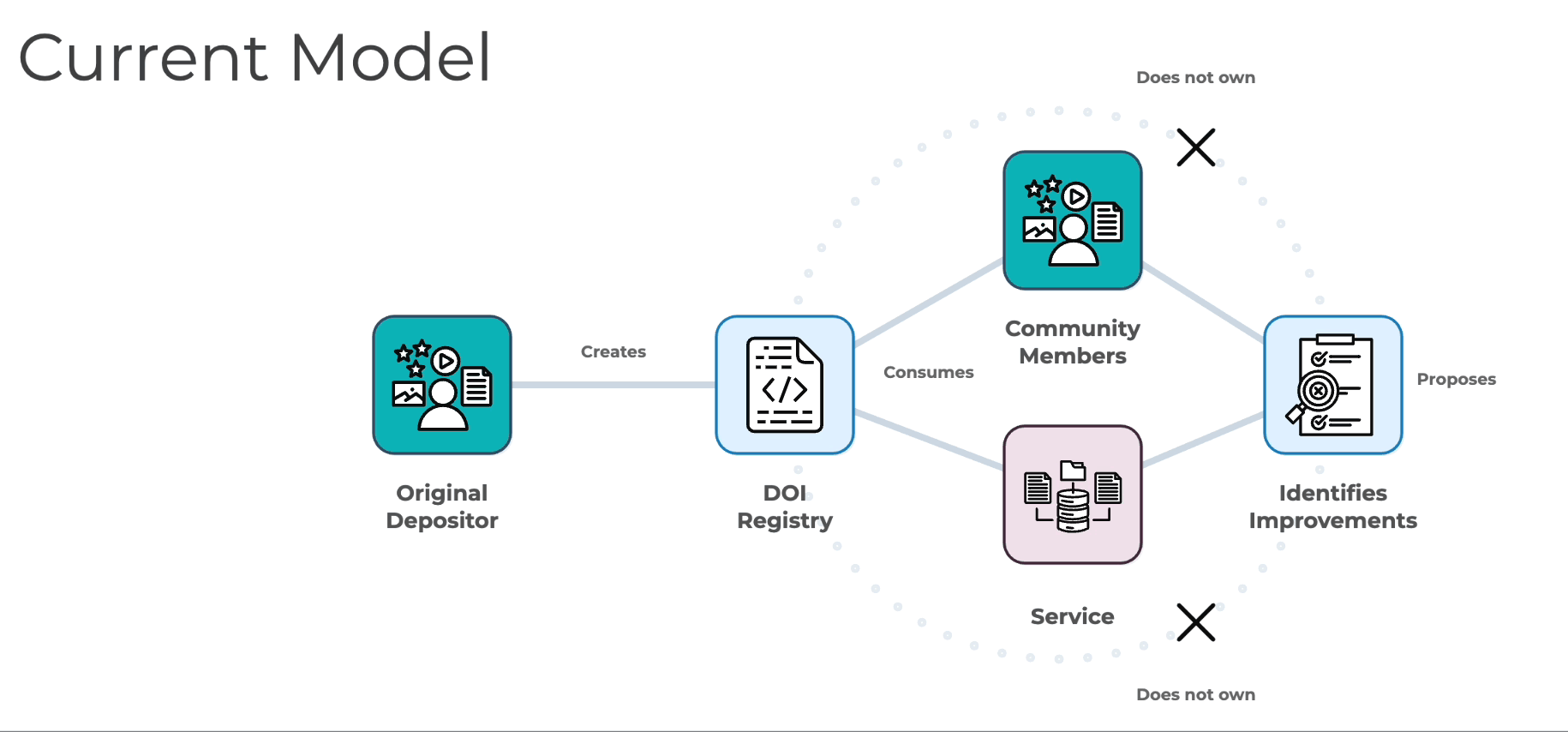
Adam provided an overview of some of the discussions that have happened to date and the limitations of the current model for maintaining DOI metadata.

(slide 13)
Adam reiterated the conveners’ appreciation for persistent identifiers and how they form the core of our infrastructure. PIDs and their metadata, he commented, provide an authoritative source of truth for identifying and tracking research outputs, allowing for seamless exchange across services and platforms. He noted that this system has flourished over the past 20+ years and its success should be celebrated. The work of COMET is to make DOI metadata better, rising to and evolving with the needs of its community.
(slide 14)
Adam explained that the primary impediment to this is a limitation in how DOI metadata is produced and maintained. He explained that DOIs operate on what we could call a ‘push model’, meaning their metadata is produced by some entity, who then registers it with a service like Crossref or DataCite. From that point forward the creator is the one solely responsible for its upkeep. Even if others in the community discover errors in what's been registered or could improve the metadata, it is only the original depositor who can make any changes. If the depositor lacks the ability to make these improvements, or simply doesn't see the value in doing so, the metadata remains incomplete or incorrect.
He then noted that even if this metadata is frozen in place, everything built on top of it is in a constant state of growth and development. Research assessments become more sophisticated, funding compliance grows more complex, open access agreements require more detailed tracking of where work is being published. In order to be effective, the underlying metadata has to be continuously improved to keep up with these changes.
Adam explained that what happens in response to this push model limitation is that the community routes around it by working outside the DOI ecosystem. Work is done in services to fill the gaps in DOI metadata, adding back what is missing but necessary for real world workflows. Here, he noted, is also where things can become problematic and unstable. These service level enrichments result in a fragmented landscape, where improvements exist in isolation disconnected from the broader ecosystem.
This fragmentation was described as manifesting a few different ways:
By creating large scale inefficiencies through duplicated effort. Where one organization invests time and resources in improving metadata, those improvements remain trapped within that system. Other organizations, then, have to repeat the work, multiplying total cost and time spent.
By introducing significant operational risk. Service-level enrichments are often siloed within specific commercial offerings or similar platforms. If an organization loses access to them, whether due to cost, a service being discontinued, or simply strategic changes at their organization, they can also suddenly lose years of careful curation work.
By undermining authority and consistency. PIDs were meant to reconcile information across different services, but when enrichment is done at the service level, it can result in different, potentially conflicting improvements to the same metadata without any path towards resolving those differences.
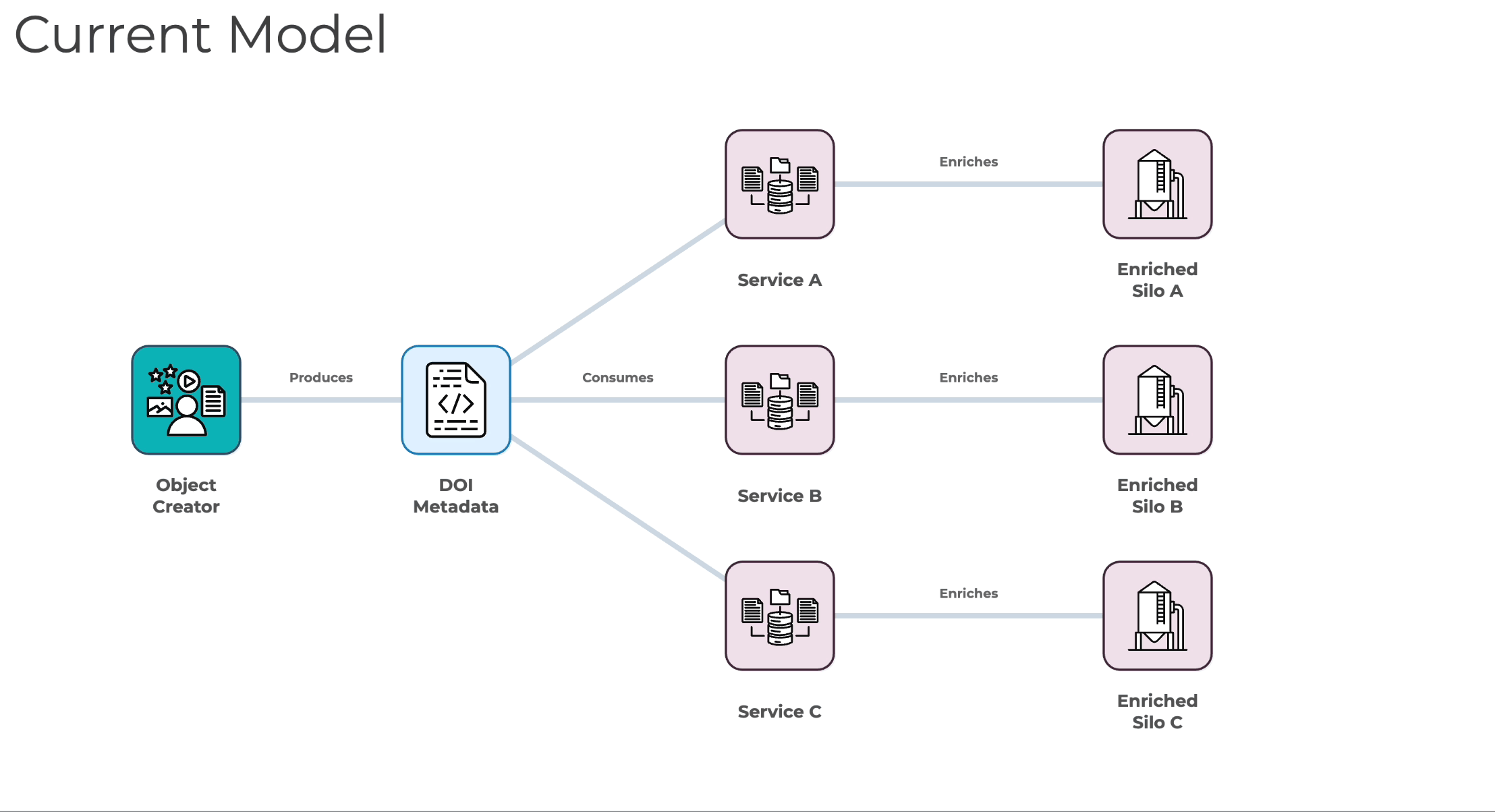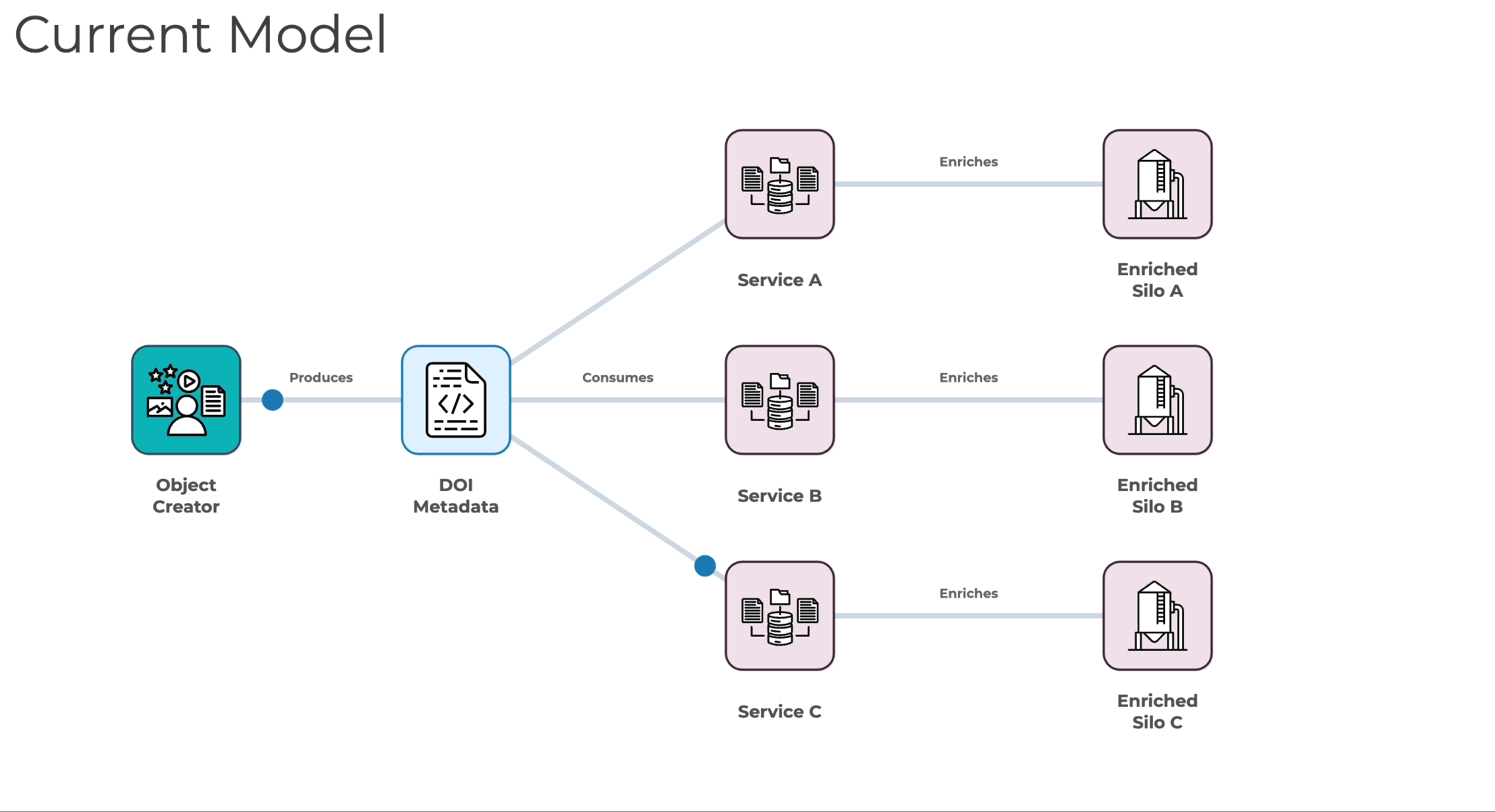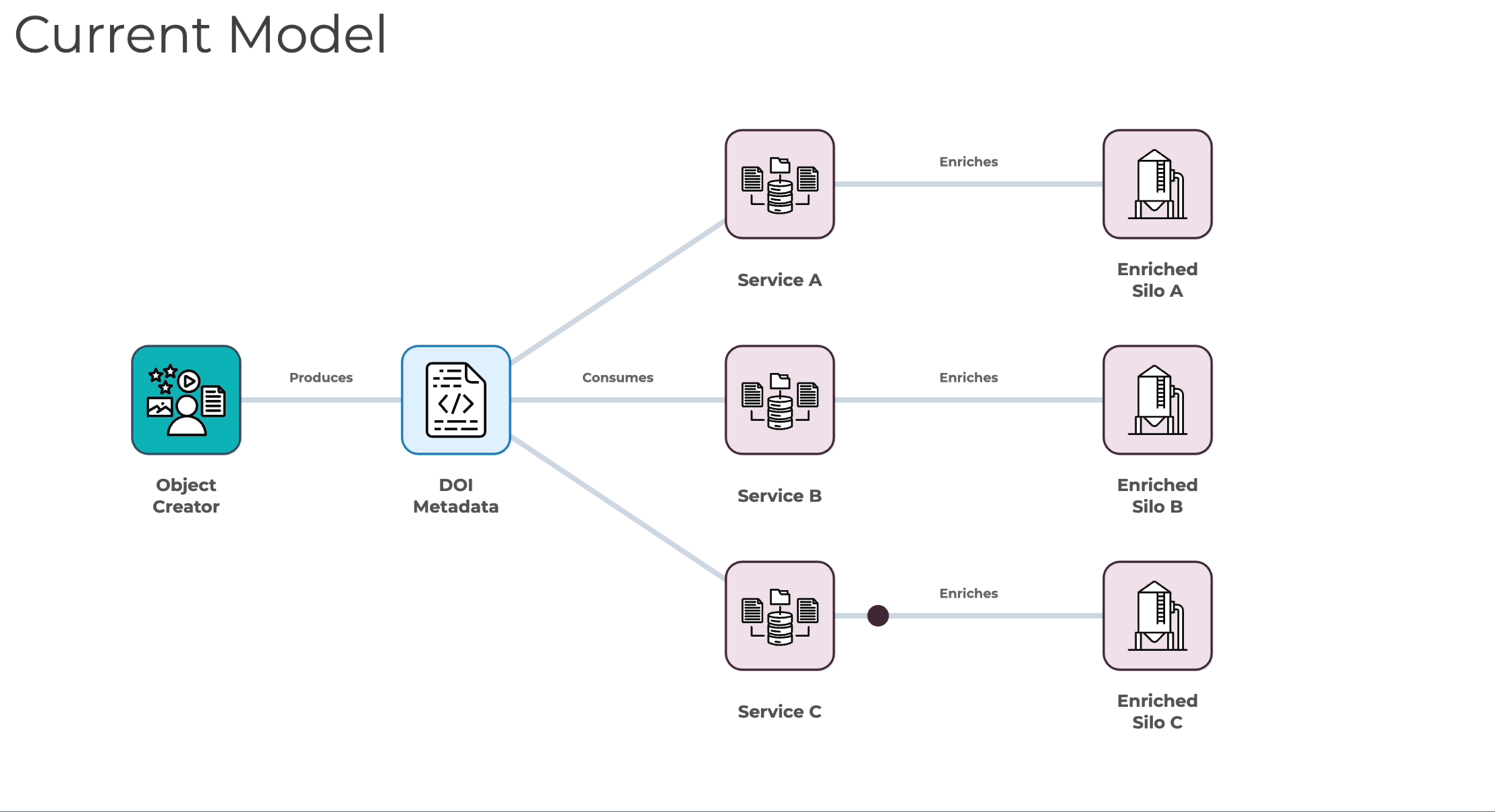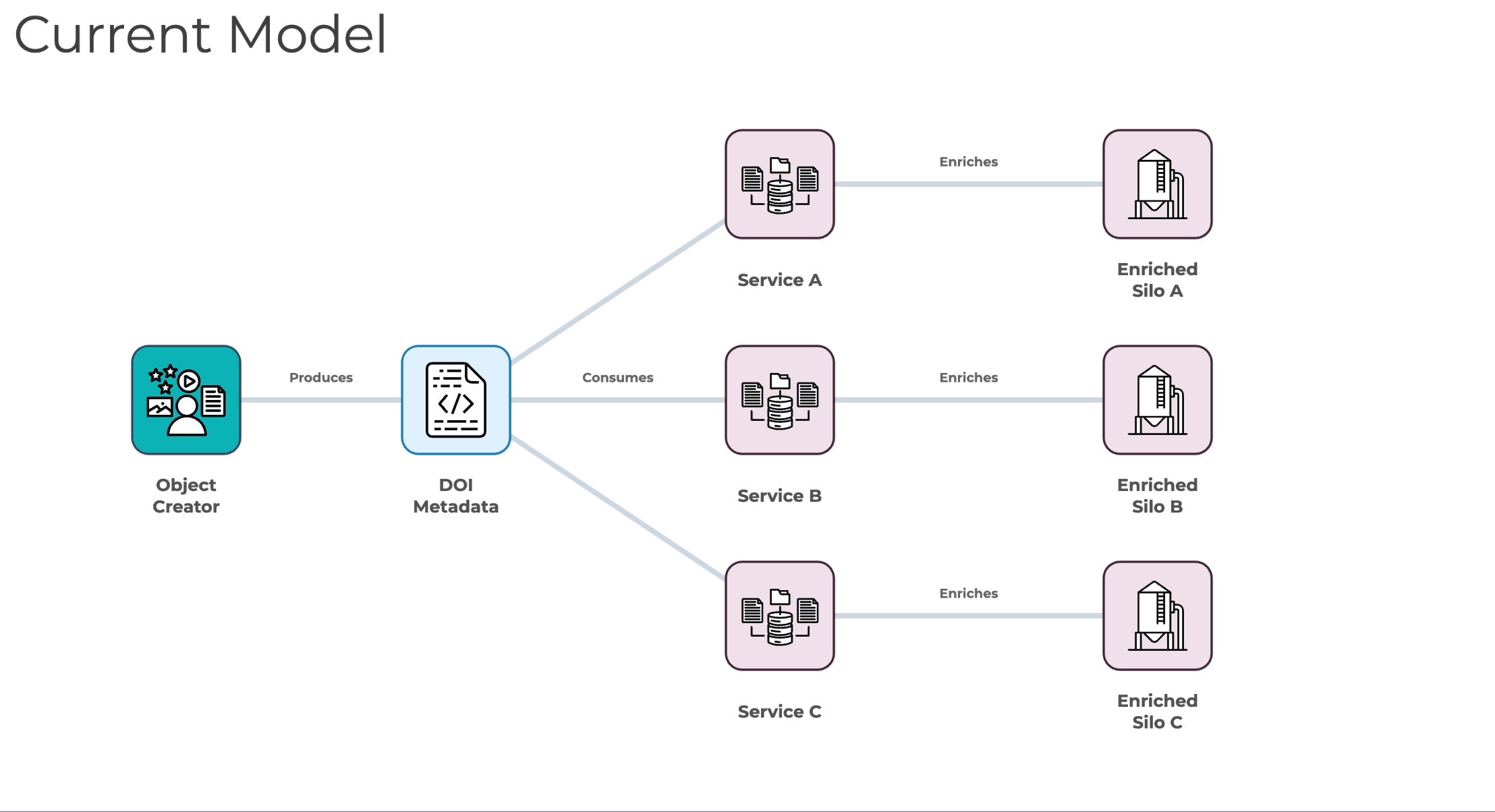
(slide 16)
Adam then posed a question, “what if we could change this model, creating a system that maintains the authority of DOI registration while embracing the enrichment being done by our community?”
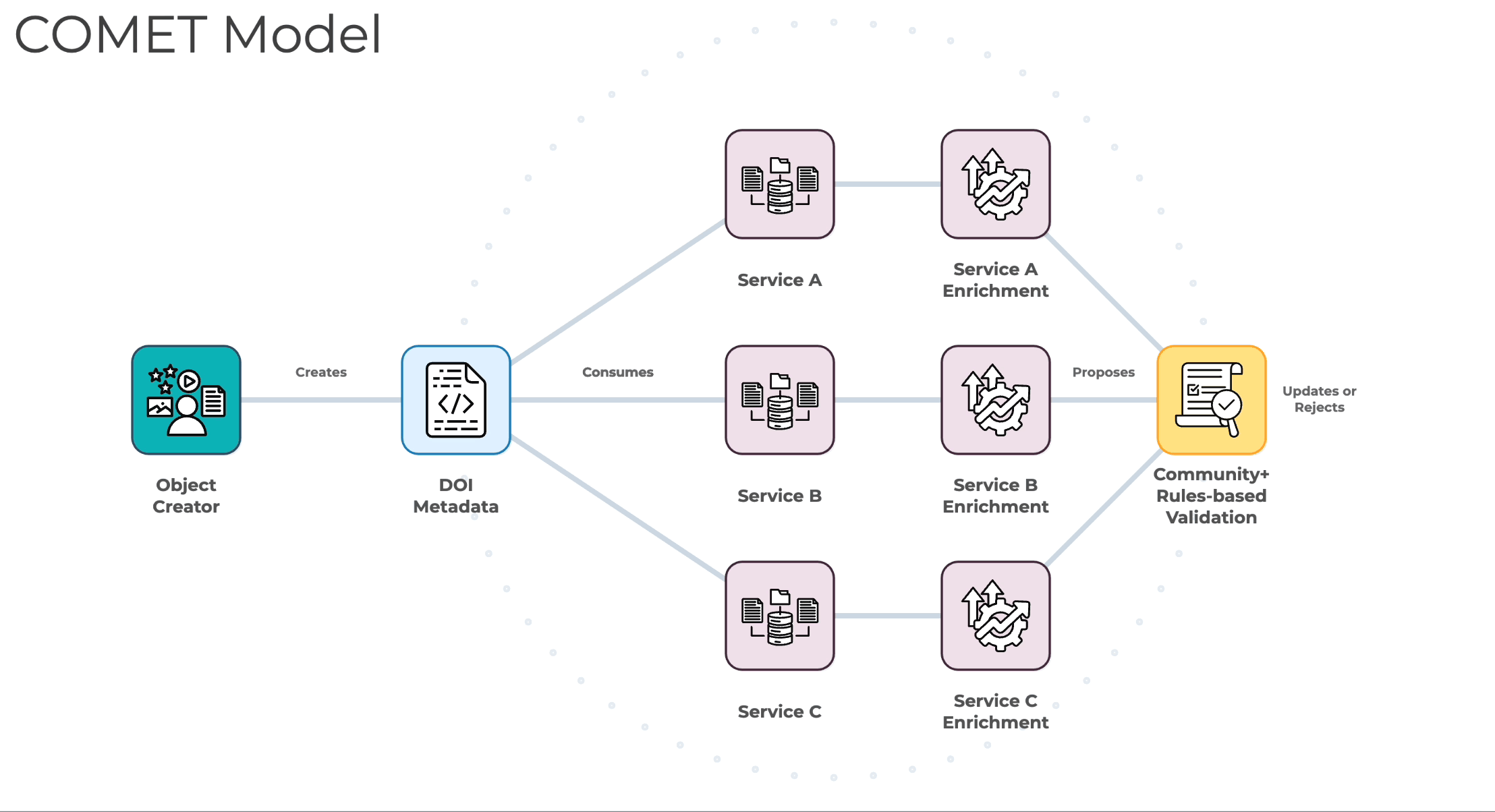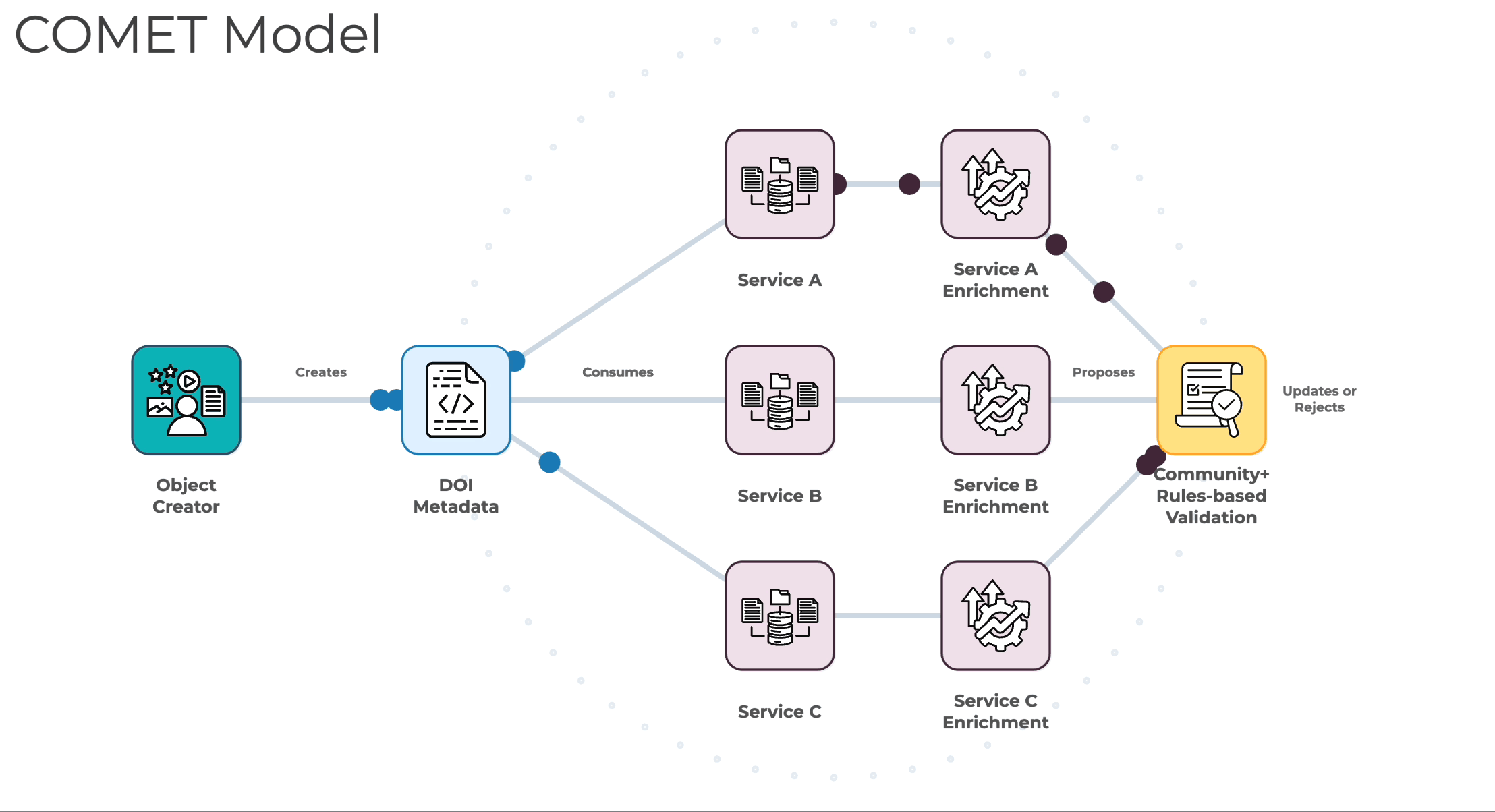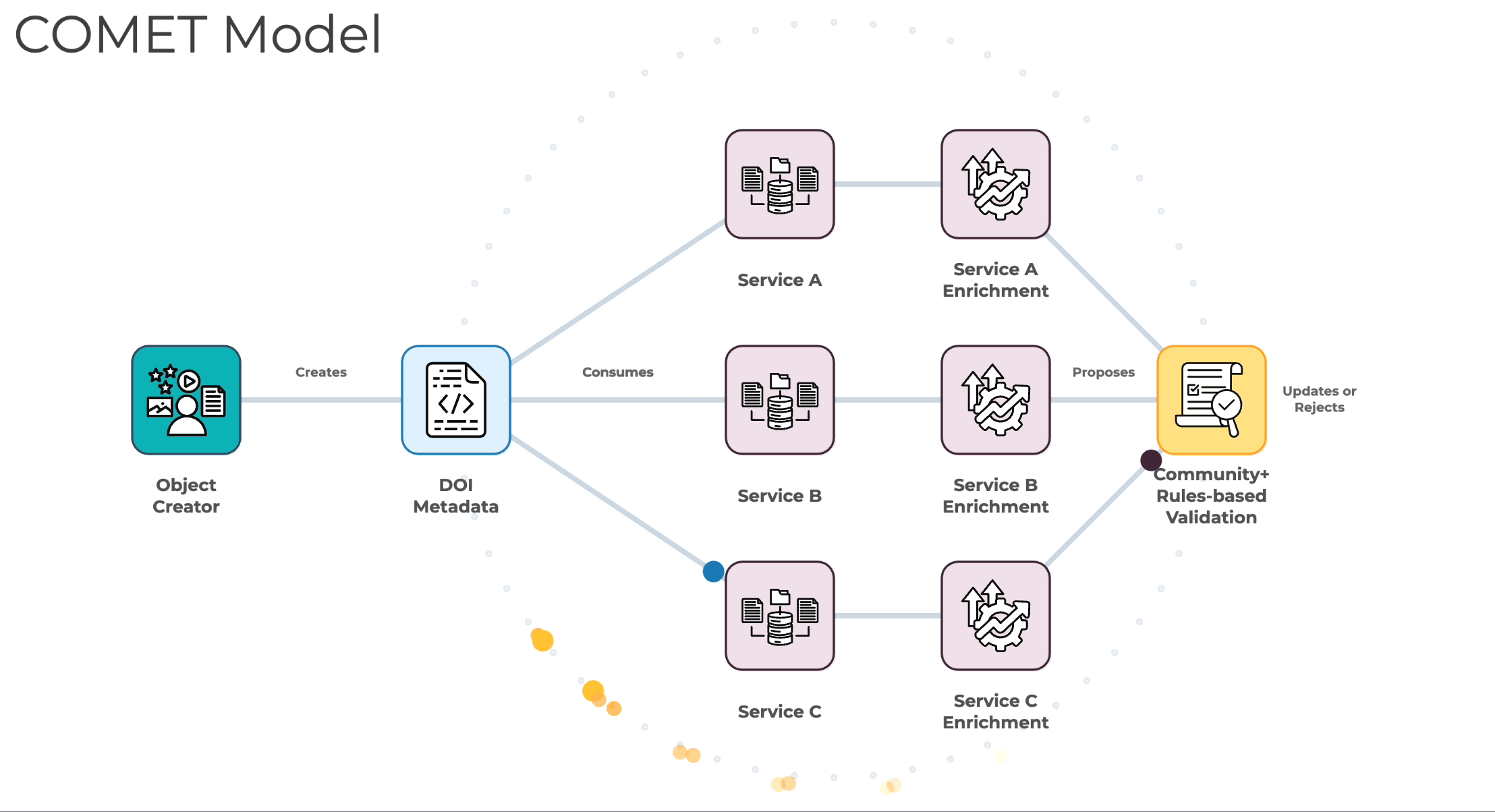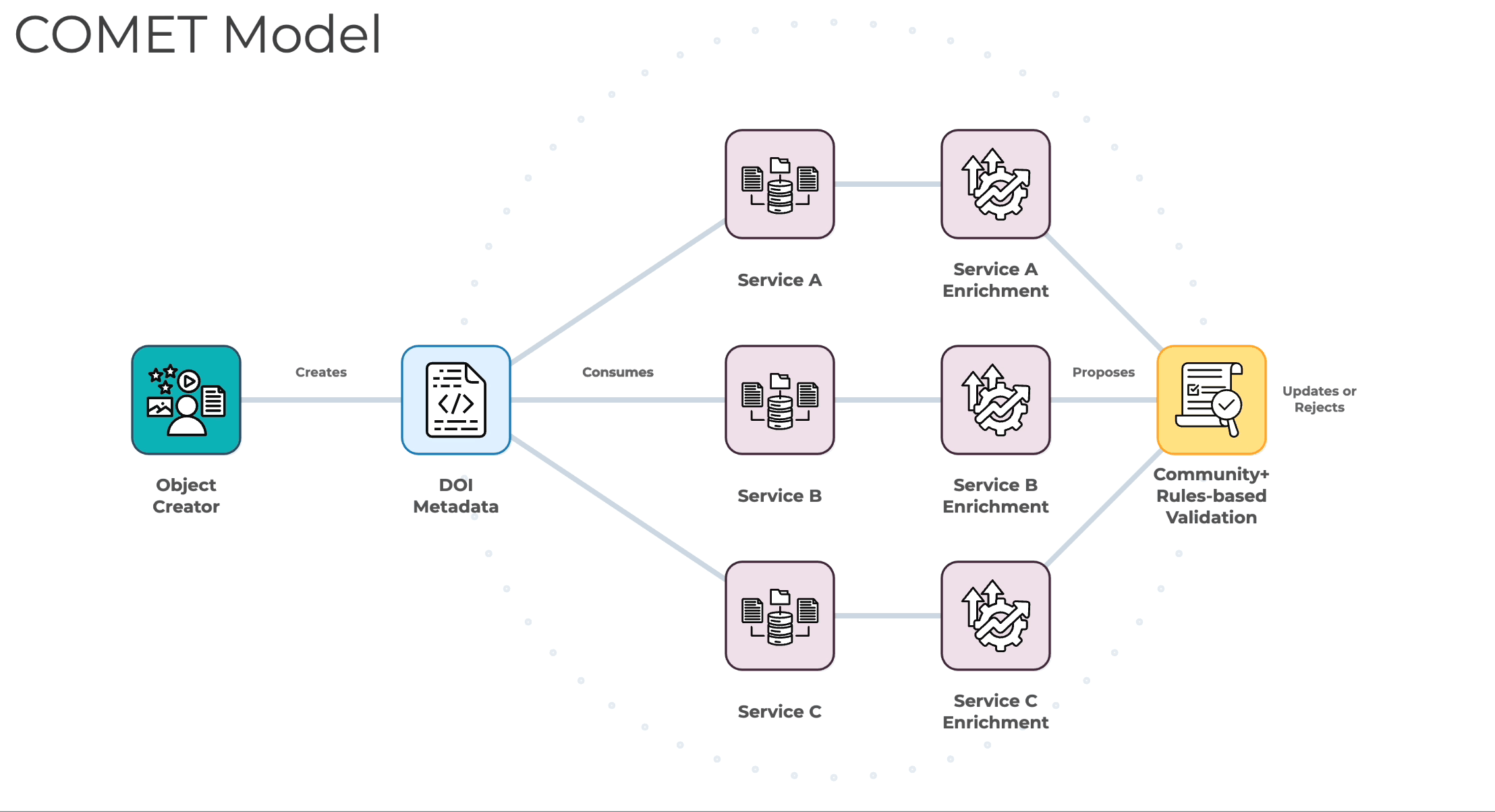
(slide 19)
From here, Adam presented an alternative model, wherein enrichments are not bound to specific services, but instead decoupled, allowing them to exist independently, and be shared in a format that any service can produce a validation. Their integrity and quality could then be guaranteed through combining various forms of automated rules with expert review, while also carefully tracking the provenance of improvements. This would create a clear, trusted path for enrichments to flow back to the sources of truth, removing that fundamental limitation of the push model of DOI metadata. If enrichments were decoupled in this way, he argued, the whole community could then validate and build upon them. Organizations could switch systems without losing years of effort. The community could leverage the strengths and focuses of different services, while ensuring that improvements remain accessible to all, even if these services change or disappear. Most importantly, validated enrichments would become part of the permanent authoritative record, allowing for a system of constant refinement, where every enrichment strengthens the shared foundation of DOI metadata, regardless of where the improvement first originated.
Adam then commented that although this approach sounds ambitious, the community has already been successful in using such a model through ROR - the organizational dataset feeding myriad different services, being constantly improved and refined by the community independent of any one case. He stressed the importance of navigating challenges by using the same product principles that made ROR effective as outlined below.

(slide 21)
Discussions chaired by John Chodacki
The presentations paused at this point in both sessions to make way for clarifying questions and discussion.
Questions and responses included:
Clarification on the scope of COMET including:
Whether we are aiming to build a system within the time specified or if we’re only defining the problem
Clarification was given that COMET aims to articulate the problem and a prospective solution
If COMET is focusing exclusively on DOI and PID metadata
Clarification was given that COMET will likely initially focus on DOI metadata, limiting the scope to where we think we can have the most immediate and achievable impacts. It was noted, however, that this scope may broaden once the initial work has been completed and that such approach is not intended to discredit or exclude additional or alternative paths, only to focus on completing real and near term work.
The Taskforce
Who the Taskforce members are
Response was given that the Taskforce membership was built through the networks of Crossref, DataCite, CDL, PKP, as well as interested parties in the PID community who are invested in and fully understand the underlying workflows. It was then noted that it’s important to ensure that COMET works with people outside of these immediate communities and that the Taskforce takes steps to identify and solicit participation where these gaps are identified.
It was also clarified that a list of all participants involved would be published on the COMET website.
How widely spread does COMET conceive the community? The currently participants are mainly English-speaking
It was agreed that COMET needs to broaden its geographic scope to ensure inclusion of more voices from around the world in the conversation, and that action will be taken accordingly.
If there is a plan to cooperate with publishers
Response was given that there are already publisher representatives participating in the Taskforce
The Workflow
How conflicting assertions are expected to resolve.
Response was given that in the context of ROR, the way this is generally resolved is relative to whatever the specific source of truth from which the assertion was derived. If it’s in the case of a specific research output, where we have conflicting assertions, we would either resolve them relative to said work or through some form of dispute resolution. It was also noted that OpenAlex has experience with these kinds of problems, is a Taskforce participant, and can help us navigate them.
Examples of entities that enrich DOI metadata,
Examples were provided of several groups who do this work: commercial services (like Web of Science, Scopus, and Dimensions), non-profit discovery services like OpenAlex, research projects doing bibliometric work, as well institutional reporting groups. It was also clarified that while traditional library cataloging efforts also handle metadata, they typically follow different workflows than those used in PIDs.
A comment was made that it’s important to have good case studies highlighting how incorrect metadata has affected our communities, which was met with agreement from several participants.
Vision Statement: John Chodacki
Following the break for discussion, John introduced the concept of a vision statement to the group, with the intent of having them produce such a statement, describing COMET’s goals for and anticipated impact.
The suggested format for the vision statement was:
‘For [our target group], who [group’s need], the [product] is a [product category or description] that [unique benefits and value].
Unlike [current methods], our product [main differentiators].’
A draft product vision statement was then shared for comment from the group:
“This project is a collaborative framework for metadata enrichment, designed specifically to improve the quality, accessibility, and interoperability of metadata across diverse platforms. Unlike existing approaches, which often focus on isolated improvements within specific ecosystems, this project will create a unified, community-driven model that encourages contributions from a wide range of stakeholders, including institutions, infrastructure, and curators. We respect persistent identifiers as foundational sources of truth and are committed to working closely with these trusted sources to manage their metadata responsibly, ensuring that this project upholds integrity and reliability in data enrichment efforts.”
Comments included:
On the “framework
Does “framework” mean something like a shared methodology or a tangible API/tool?
Is it incorrect to think of the vision to establish a community of practice or an actual framework that is applied to different workflows?
Are we calling COMET a “framework” as opposed to something like initiative, program, model, pilot etc.
John clarified that “framework” applies to the product rather than the Taskforce.
Related to the concept of community
It was suggested that “community-driven” might benefit from more detail - which communities, and how are the stakeholders incentivized to contribute to this metadata?
Potential additions/improvements
It was suggested that including accessibility is important, but may greatly increase scope
It was suggested to add ‘open’ to the statement
There was a suggestion to include a findability aspect
It was suggested to mention inclusion of the creators of the research outputs that the DOIs describe.
There was a suggestion to emphasize completeness and consistency rather than the more ambiguous “quality," which found agreement with other participants
Clarifications
It was asked that the statement better define the contributions that are being called for
It was asked that we revise language around metadata management to better emphasize collaborative enhancement, positioning the project as a partnership that amplifies existing work.
Additional considerations
Additionally, it was suggested that we account for metadata licensing requirements
That we consider regional variations and restrictions in the handling of metadata
The vision statement section of the session was concluded by John’s confirmation that a draft of the statement would be circulated for further comment from the Taskforce, which the conveners would then refine before publishing on the Taskforce’s website.
Next Steps: Clare Dean
The session was concluded by outlining the next steps for participants:
Participants were asked to provide feedback on the vision statement
They were also told that they would receive invitations for the listening sessions
Participants were asked to respond to surveys and polls related to COMET’s work
Participants were asked to consider who else should be part of the Taskforce and encourage their participation, relaying to Clare
All participants were told that they would be provided with materials relating to the Taskforce to help spread the word about and advocate for COMET